
文 / 罗霄
整理 / 田沛松
校对/ 朱韵
感谢蓬岸和网络社会研究所的邀请。我之前在艺术类和设计类的院校做过很多分享,当然还有技术专业,包括同济大学建筑学院。我也向蓬岸了解了一下大家这个群体,之前确实还没有与大家这样的群体做过深度地分享,所以今天我是也非常激动。
我自己是创意技术专家和数字艺术家,这样一个身份比较分裂,涉及技术和艺术两方面。但其实和跨媒体艺术学院做的事情是基本是一致的,就是以科技为主的新媒体艺术。我可能更多的是在做一些实践类的内容。一般的对外推送里,最近我都会把自我介绍改成算法工程师和数字艺术家,因为“创意技术专家”这个身份总需要向人解释,解释我具体是干嘛的。但是在我们跨媒体这个环境里我就会觉得很轻松,所以我把title又拿回来了——Creative Technologist。
比较早开始,我就一直在做游戏开发和新媒体艺术这类的商业项目,也包括一些艺术项目。大概从2020年开始,我逐渐把AI引入到一些创作中。今天的主题我想以自己的创作实践为主线,从我的视角来分享一下AI:到底什么是AI?什么是AI的生成?在AI普及之前,我们跨媒体一直在做的算法生成艺术(Generative Art)和现在的AI生成有什么区别?它们中间有哪些差异和联系?以及新技术对艺术家作者身份的定位,或者说给艺术家的主体性带来什么影响?但在一开始的时候,我会先讨论一下人工智能与机器学习。

最重要的是了解什么是函数(function)。关于这个问题,我们有中学数学知识就足够了,虽然大家可能是文科或者艺术类的专业,但是其实中小学课本里已经有函数这个词。其实函数主要指一种方法,在我们编程和算法的世界里专门有一类编程思想就是把函数翻译为方法,而不叫函数。当你把函数认为是方法的时候,它便可以解决一系列社会和人生活中的问题,尽管这种方法或者说这种函数往往非常复杂,比 “y=x+1”这种简单函数要复杂得多,但是它们都是解决某一类问题的方法。在人工智能或者机器学习之前我们需要回顾一下“人力”学习。当我们说要解决一个问题,其实就是寻找到一个方法,寻找一个函数。

我们出一道稍微有点难度的初中数学方程式——“y=ax+b”。如果我们给定了几组已知的数据,比如说“x=1”的时候“y=5”,“x=5”的时候“y=13”,这些是我们已知的数据,然后我们需要求它的参数a和b分别等于多少,我们有了一个方程式“y=ax+b”,但是因为a和b这两个参数是不知道的,所以你没办法用这个方程去解决某一个问题。
但是当我们有了几组已知的数据:“x=1时y=5”、“x=5时y=13”,那么这时我们就可求a和b分别等于多少。我们把它代入方程以后,就会得到a=2,b=3。也就是说当a和b找到的时候,这个方程就有用了,因为它这个时候变成“y=2x+3”了,这时如果你给定一个x你就会得到一个新的y。比如x=30时就会得到y=63。通过已知的几组数据得到这个方程式的参数以后,我们就可以用新的数据得到新的输出,这就是“人力”学习的过程——对某个函数求解的过程。那么“机器”是怎么来学习的呢?

最关键一点是机器它会自主地从已知数据中寻找一个函数,所以我们会把这个机器学习的过程叫做模型训练。还是这个方程式“y=ax+b”,还是先通过已知的几组x和y找到它的参数,a和b找到以后这个方程就固定下来了,当然这个时候是机器自己去找。这样这个函数就可以用了。如果你的x是一个提示词,那么你的y就是输出的一张图。只不过这个时候的函数非常复杂,它不是“y=2x+3”这么简单的一个方程,给定输入提示词然后拿到一张输出图,这种方程式可能是我们人类很难写出来的,但是机器可以通过它的学习能力把复杂的方程式找到,这就是机器学习。但最重要的一点是为什么机器能学习?机器为什么会自主学习?这就很神奇的一点,实际上这与最基本的一个算法叫“梯度下降算法”(Gradient Descent)有关。
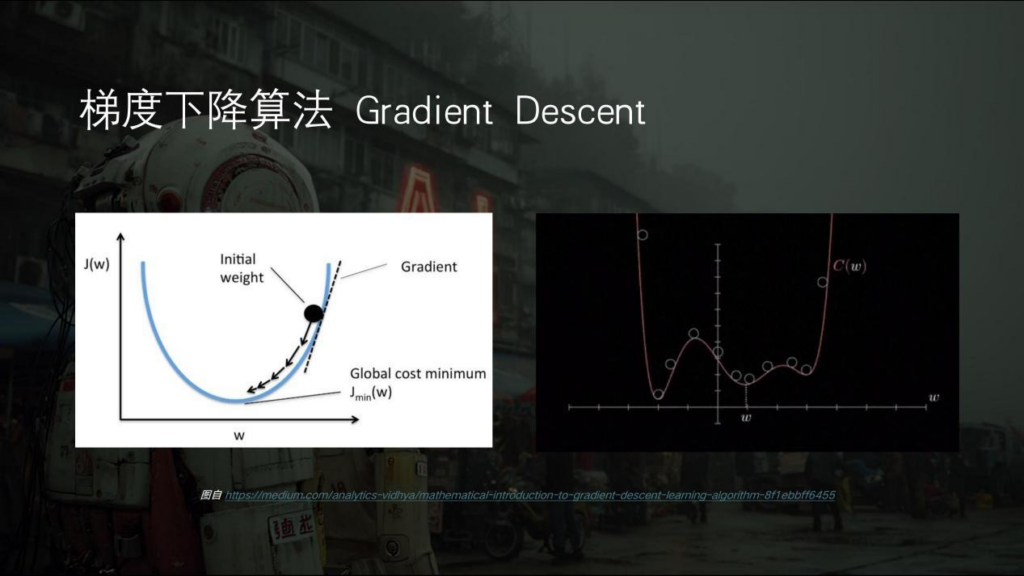
其实只要我们稍微分析一下,机器学习并不是那么神奇。比如说这样一条抛物线,它是一条曲线,那么对于这个黑色的小圆球,我们通过梯度算法或者说求导数的方式,就可以求每一点接触于曲线的那条虚线,也就是它的斜率。偏左或偏右,在数值上会反映为这个值大或者小。那么我们让这个球稍微移动一点点,往下走一点或往上走一点,相应地,它当前斜率的值就会变大或者变小。只要人为规定让球一直往着变小的方向去走,那么这个球便会自动地朝最下边移动,也就是说它会有一个自己寻找、求解的过程。
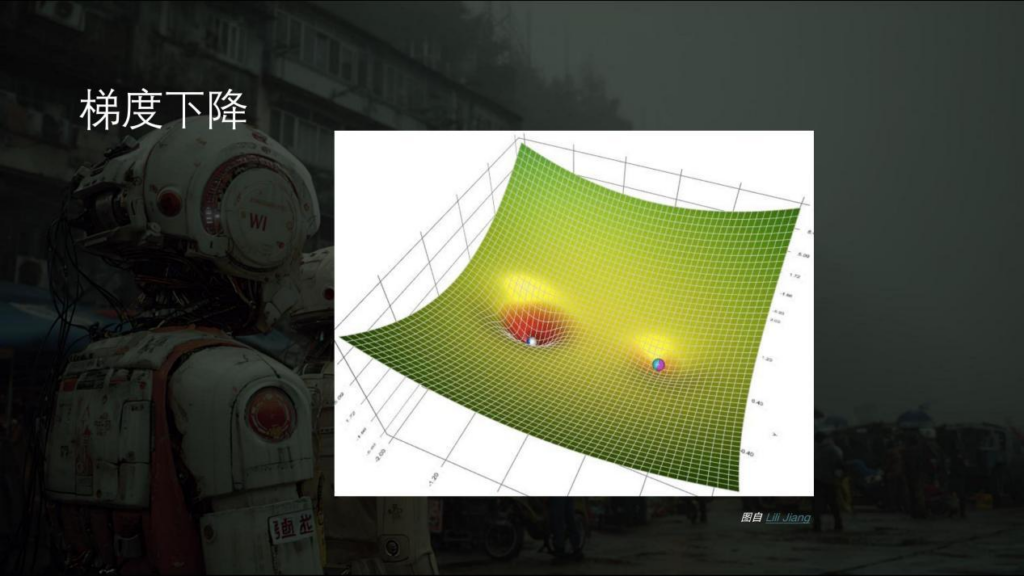
从三维的空间里来讲就会稍微直观一些。我们有一个复杂的问题,这个问题有两个答案,一个答案是深一点的坑,另一个答案是浅一点的坑,不同的坑可能对这个答案的完善度是不一样的。可能深一点,大一点的坑回答的更准确一点。当我们把一堆的球在任意的地方撒手之后,这些球其实梯度下降的,你也可以认为有一个重力很自然地拉着它往下走,所以球会自己寻找离他最近的坑掉进去。其实这就是它自己去学习和自己去找最优函数解的一个过程,也就是机器学习比较直白的一个讲法。其实没有什么玄学在里边,而是很正经的数学公式。

所以机器学习就是通过算法,让计算机从数据中进行学习和改进,继而让机器拥有学习的能力。机器学会了从数据资料中寻找函数,对于“y=2x+3”,给定机器一个x就能得到相应的y,但是真正的方程要复杂得多,人手写不出来。
我们再举几个例子,比如ChatGPT这种大语言模型。当你问ChatGPT:“什么是机器学习?”,那么它会先回答一个字“机”,然后是“器”,这样一个字一个字地输出。我们在去年用ChatGPT的时候,你会发现他吐字的时候很慢。因为它其实是先把“什么是机器学习”作为输入x,得到的输出是“机”这一个字,也就是“y=机”,然后再把这个“机”加到“什么是机器学习?”上。“机”作为一句话,再丢回给这个函数。得到的下一个输出是“器”,然后再把“机器”加到前面的问题里,就这样一点一点地往后吐字。

Midjourney这种图像生成AI同此道理,可能它的x是一只可爱的猫,它的y就是一张图。在早年间,阿尔法狗(AlphaGo)围棋也是这样。它的x输入是当前围棋局势的这张图,它的输出就是落子的位置。像这种方程人类其实很难写出来,但是通过机器学习让机器自己处理大量数据之后,它就可以写出来。机器学习的应用有一些常见的种类,比如回归类,通常是应用于预测,包括预测天气以及Pm2.5等等;还有给事物分类,比如说画面里有猫有狗的两组照片,它会自动地帮你把猫和狗做区分。其实我们现在每天都在用AI,所以大家会觉得这是自然而然的事,实际上这都需要通过训练来学习。如果你在训练AI的时候给它很多猫的照片,并告诉它这是狗,那么等它学习之后,你再给它一张新的猫的照片,它就会告诉你这是狗。这其实和小孩一张白纸的状态一样,你教他什么,让他学什么,怎样去引导他,他最后就会学成相应的样子。还有一类是我们现在用的最多的生成式学习(Generative Learning),对应到我们今天的主题。我们日常生活中会用生成式AI去生成文字、生成图片,生成视频,生成各种多模态的内容,其实像大语言模型、图像、音乐等等绝大部分,都属于生成式AI的范畴。
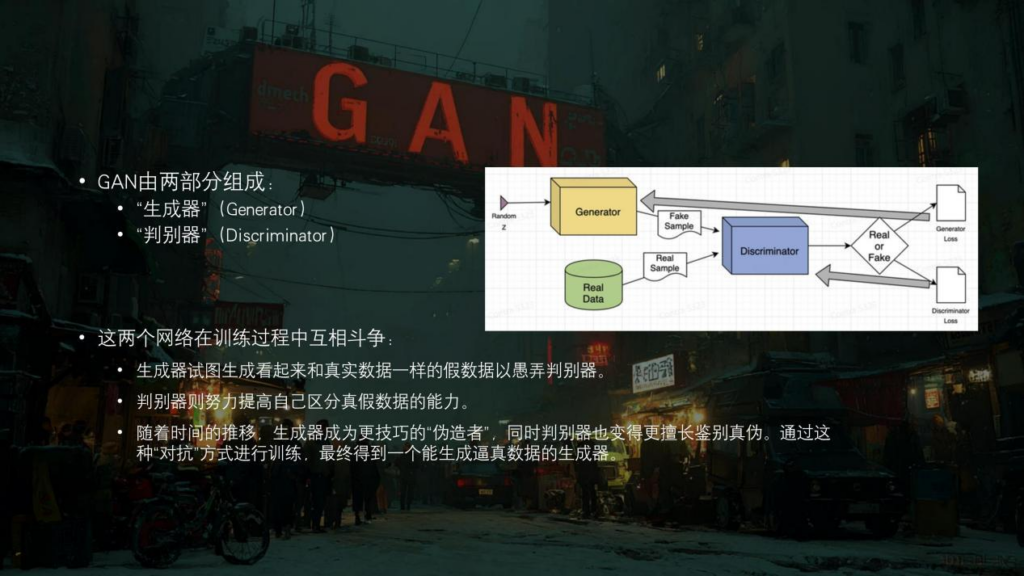
我首先会讨论一下在前几年比较流行的一类生成模型——生成对抗网络(StyleGAN)。这个词可能在一些论文里会出现比较多,因为现在大家日常用的是扩散模型(Diffusion Model)以及扩散模型的一些变体,但是“扩散模型”这个词写在文章里感觉就不是那么亮眼,而“生成对抗网络”这个词写出来就很好看,尽管它的名字是很技术性的。那我们来看一下什么是生成对抗网络。它包含两部分:生成器(Generator)和判别器(Discriminator)。生成器的功能就是不断地生成一张图,然后判别器就会来分辨这张图是AI生成的假图,还是一张人类真实数据里的照片。当判别器做出正确判断以后,生成器会接着进化,直到生成的图或者结果非常接近真实的数据,让判别器判别不出来的时候。这时二者间所谓的对抗或者说博弈就到达了一个平衡点,那么这个模型就已经被训练为比较完善的状态,这是生成对抗网络的一个特点。
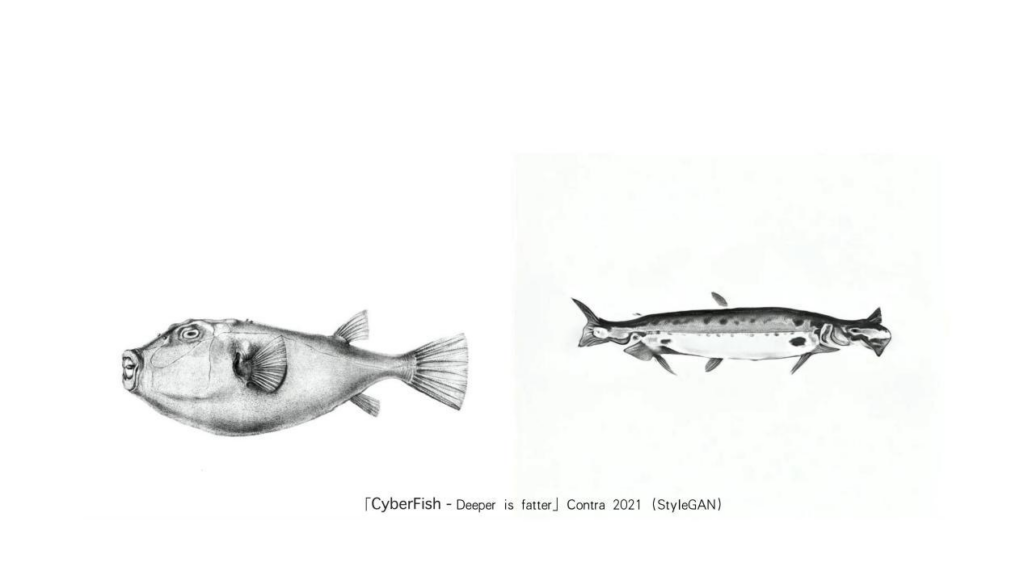
我接下来会以自己的一些作品创作过程来讲这些生成式AI,包括生成对抗网络,以及扩散模型背后的原理。《CyberFish》是从21年开始就在做的一套系列作品。那个时候还没有扩散模型,是用StyleGAN通过提示词来生成的这些鱼。作品的世界观就是一条普通的鱼,在种种事件冲击下有了一些分化和变异。那么它从左到右就会有一些视觉方面的进化,这些可能现在看都有一点粗糙,但还是很好用的。这同时也暴露了现在模型的问题:现在的模型生成的东西都太完整了,也挑不出问题来,想让它不太完整反而不是那么容易。但是以前的模型生成出来就很“艺术”,打引号的艺术。比如说中间这条鱼,它进化成身体里有一个城市的状态,那么我就来给大家分享一下它究竟是如何完成进化的。

在做鱼的时候,我首先要有模型,模型需要训练,所以我就要先收集数据。数据集就是这些生物学的插画,它们来自于一些生物学的网站和生物学书籍的插画。但拿到数据之后,不是马上就可以开始训练的,我还需要进行一些前期的,所谓数据清洗的工作。这实际上也是很直白。因为我要训练鱼的图像模型,那么每张插画里的文字注解对训练图像就是有干扰的,所以我其实每张图都做了一些P图的工作,这个就是数据清洗。

当数据准备好之后,我可以开始训练了。现在你看到这些都是训练过程中生成的一些鱼,它还没有训练完毕,但是远看的情况下已经能看出来是鱼了。不过你仔细看的话有一些是不是不太对?像右边这条鱼,它的鱼鳍和身体是分开的,然后像上边第三条,它没有下巴等等。也就是说如果模型没有训练好,作品从工业指标和数值上来讲是不达标的,而且这些图像,作为从人的像素空间看到的事物,也是不符合人的常识的。但如果你做一些艺术创作,比如说故障艺术之类的东西,还是挺有趣的。

当模型训练好以后就可以生成图像了。现在你看到的都是模型训练好以后生成的鱼,这个鱼就是有鼻子有眼的,一切都都很完善。但是也有一些特例,就像上边的第二条鱼,你可以看到它这条鱼左右两边都是尾巴对吧?这就是因为从技术角度来讲模型训练的不是百分之百精确,不是那么好。所以对应的生成内容,自然会有一些东西是不符合工业标准的,但是它可能符合我的创作标准。如果都是跟原数据一样的鱼,就没有意义了。

这个动画叫插值动画。什么叫插值?我们假定有1和10两个数字,AI会自动的帮你把中间的2、3、4、5、6、7、8、9连起来。另一个概念是,一个数对应一条鱼,也就是一张图。你从像素视角里看到的一张图对应的是其实AI的数学空间,也就是“潜空间”(Latent Space)。那个空间里是一系列非常复杂的数字,但总是一个数代表一条鱼。假定1是一条瘦鱼,10是一条胖鱼,AI会自动的把你2、3、4、5、6、7、8、9所对应的插值表现出来,当然这个是线性插值。每个数对应一条鱼,当你把这10个数对应的鱼连起来播放,就会得到这种非常顺滑的动画,这就是插值动画。还有一个特性,比如左边这条鱼,我给模型的鱼是生物学插画书里真实数据的鱼,右边是我训练的模型生成的一条鱼。当我给我的模型去看左边这条鱼的时候,我的模型就会从AI的数学空间里找到最接近左边鱼的一个状态,并一点点去逼近它。正如我前面所说一张图对应一个数。假定左边这条胖鱼对应的是100,那么我的AI就会从他的数学空间里找到最接近100的那条路径逐渐去逼近100,反映到视觉上就是有一条鱼它自己越吃越胖。所以这个作品就叫《CyberFish 变胖》。
还是同样的原理,这件作品叫《CyberFish 支楞起来》。因为我给AI的目标是一条狮子鱼,它身上有一些鱼鳍是像刺儿一样,然后AI会无限地去趋近它。而这个叫《CyberFish 左右为难》。因为这种鲨鱼叫姥鲨,是一种深海鲨鱼,它非常柔软瘦长。尤其是左边这张图画里展示的,它的头可能有一点像尾巴,然后AI就不知道哪边是头哪边是尾巴。其实它只是纯粹的从像素的角度要不停地去趋近,它不会停到最后一帧,而是无限去接近左边,最后会大概停到一个它觉得已经最接近的一个状态。但是我们人去看,当然它生成的鱼两边都是尾巴。这个问题就跟你模型的训练工艺以及迭代的部署有关。但总之,AI有一个能力就是去无限地趋近,只要你给它一个目标。

我们现在来看鱼是如何进化的,从左边一条普通的鱼进化成一条有赛博朋克风格的鱼。进化其实有两个关键点:一个是你要有一个生成模型,我刚才已经训练了一个可以生成普通鱼的模型。然后还有一个点是你要给他一个clip。这个clip模块是干嘛的呢?我们看到左下角是一条普通的鱼,它对应着一个很复杂的数,我们一般把它叫矢量(vector),然后把这个代表普通鱼的数字丢给神经网络,再给它一句提示词,它就会生成一条武装起来的赛博朋克鱼,一条风格化之后的鱼。能做到这样的关键就是clip的存在。它首先能理解这个语义。另外的一个作用是引导,就像你倒车入库,你的教练会让你往左打一点,往右打一点这类的引导。Clip会引导着你的生成模块向你的目标(target)去。也就是说在AI生成的逻辑里,你的提示词就是生成任务的一个目标,不管你生成文字也好,图像视频也好,提示词都是它的target。当我们把这个过程可视化下来,就得到一条普通的鱼,由clip引导着生成模型无限地去接近于那个目标,最终变成了一条风格化后的鱼。
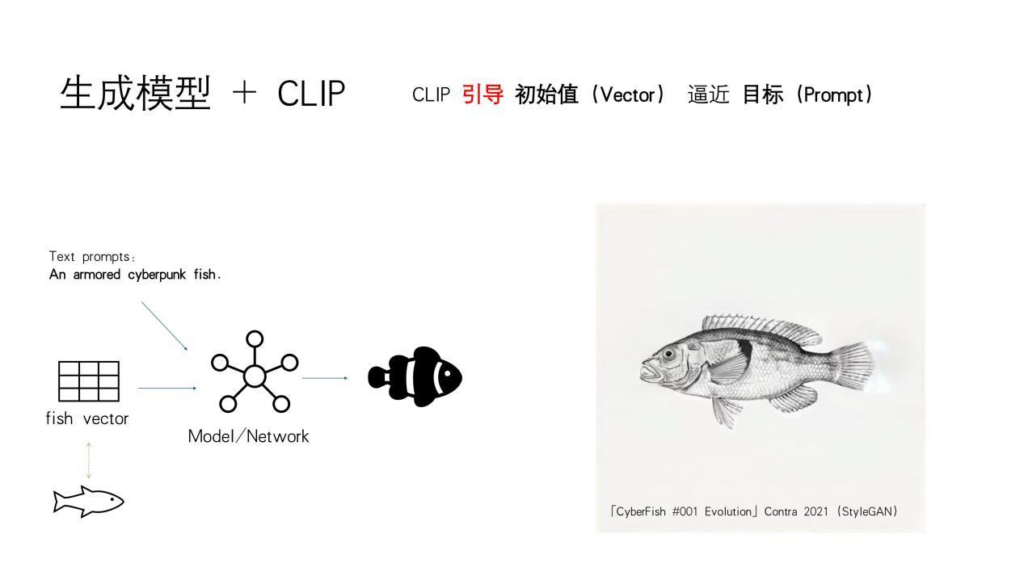
当解决了这个问题后,就可以用AI生成很多这样的鱼,从一条普通的鱼开始这一系列。我后来也参加了一些展览和一些加密艺术的活动。但我们不会每次生成的时候都给AI一张图,我通常只给它一个提示词,比如“一条武装起来的赛博朋克鱼”,这时候AI会自己从它内部拿一个随机数,也就是一个噪声(noise)作为初始值,从噪声值开始无限地去接近于作为目标的提示词,所以也会得到一张图。这个过程就是所谓的“文生图”(text-to-image),有了文生图以后,做事情就非常简单了。

《CyberFish-Front》这个作品是22年Midjourney刚出来的时候创作的。我当时想做一组鱼的正面的作品,但是我没有那么多鱼的正脸的数据集。生物学的书里也没有,自己拍摄也拍不到那么多。Midjourneyy出来以后,我就在Midjourney里“抽卡”,生成了大概两三百张的时候,它开始出现这种看上去有点像鱼的正面的图像。当我“抽卡”到足够多的时候,我就把它们当作数据集,重新去StyleGAN里面训练,训练完以后,就用同样的套路做一些插值动画之类的,最终变成视觉性的作品。古早的AI还是很有意思的。现在的你让它生成鱼,它生成的真的就是一条鱼。

这是到了24年8月份,鱼的正面的2.0版本(《CyberFish Front 2.0》),这个时候你可以看到它已经很像鱼了。但实际上这时我反而要告诉Midjourney不要那么像鱼,要有一些惊悚的表情,像人一样的表情,比如睁大的眼睛之类的。相比第一代的时候,我要告诉它生成一条什么样的鱼,尽量生成鱼的正面。到后来要告诉它的,却更多的是一些跟鱼无关的提示词,它才可以生成我想要的东西。而且第一代的时候我是拿真实的人类图像资料作为数据集的,但这个时候我其实是拿圆环套圆环,用AI生成的内容当做数据集,去训练我自己的模型。最右边是我在它生成的插值动画的基础上加了一些算法的东西所实现的效果。
现在,我跟大家再分享一下这些鱼是怎么训练出来的。现在你们看到的这组图是狮子、老虎等猫科动物的脸。但我其实是在这组猫科动物五官的基础之上,拿它作为预训练模型,加上鱼的数据集去创作的。其实狮子、老虎的模型不是只能生成狮子和老虎,重点在于这个模型已经具备了提取动物正面五官的能力,我其实是站在这个能力之上去做自己的事。它本来是生成老虎的,但当我给它看了大量的鱼之后开始持续训练,我就成功把它带偏了。当然我也可以从零开始训练。但站在AI的基础之上训练,一是可以降低训练成本,还可以提升一些训练效果。其实我也可以基于这些狮子、老虎去训练人的生成肖像模型,重点就是这个模型它抓取五官的能力。

现在我们进入了提示词多模态的时代,文字、图像或者声音都可作为提示词,但总之这些提示词其实就是你和AI沟通时给它的一个target,你给它指明了道路,再通过各种各样的模型就可以生成很多内容。这些给到AI的原始素材以前只有人类素材,但是现在你给AI的素材有很多已经也是AI生成的,当然生成的过程离不开训练,离不开数据集。数据集可以是人类的数字资料,当然也可以是之前的AI所生成的内容,所以现在我们就更难把这条脉络解释得很清楚。前些年有的内容一看就可以判断出是人写的,但现在很多内容很难确定来自人或者AI。“垃圾”分类的工作越来越困难。
这个是我最近在做的一件事情,依旧是处理“CyberFish”的正面。但是我不想要那么多细节,而是回归到最抽象的层面。其实在StyleGAN里潜藏空间是分好多层的,从低分辨率层一直到高分辨率层。在低分辨率层的时候,它首先会生成事物最基础的粗线条,生成一个大概的形体,或者说最重要的特征。然后靠后的神经网络会再生成细节,比如鱼的皮肤,以及身上的一些纹理。如果生成一只鸟的话,就会再生成它羽毛的一些细节。但是鱼的大概形体已经通过靠前的层生成出来了,这是它最重要的特征值。我最近在尝试通过这种方式来看看AI是否有可能去创作一些抽象的东西,提取一些事物最抽象的环节,也就是最靠前的层所生成的最大的特征。当然它可以不只是图像,它也可以是文字等等。比如说现在这张图(《CyberFish 元形》)是更靠前的层生成的,其实还是那条鱼。如果继续往后边一层一层地生成,就会生成最终的那条鱼,但当生成它的层很靠前时,鱼在AI眼中其实是这个样子。

这个(《不可名状系列》)是基于插值动画和以上的原理做的一些作品,以美国大都会美使馆等艺术机构里的一些作品作为数据集,然后训练完以后生成插值动画。当然我还加了一些生成艺术的算法特效在里面。这里用到的是叫StyleGAN XL的模型,也就是StyleGAN的一个大号版本。当给它一个提示词,它生成内容的过程会很微妙,所以这组作品叫《不可名状》。其实我也不知道它是什么,而且几乎没什么可以人为控制的操作,我只能给AI提示词,比如“巴洛克珠宝”,还有一点蒸汽朋克以及其他一些元素,它就生成了这样一些影像。这也可以看作是古早类的AI艺术作品,不过其实也没多早,因为虽然AI发展很久了,但是生成式AI的爆发也就是这几年的事。这个其实也就是22年的作品,在我们跨媒体艺术的大领域里,10年、20年前就在做新媒体艺术,尤其是艺术和设计方向的同学,到现在学的可能还是Text Designer、Processing等等编程工具,而AI的大发展其实也就是最近两三年的事。

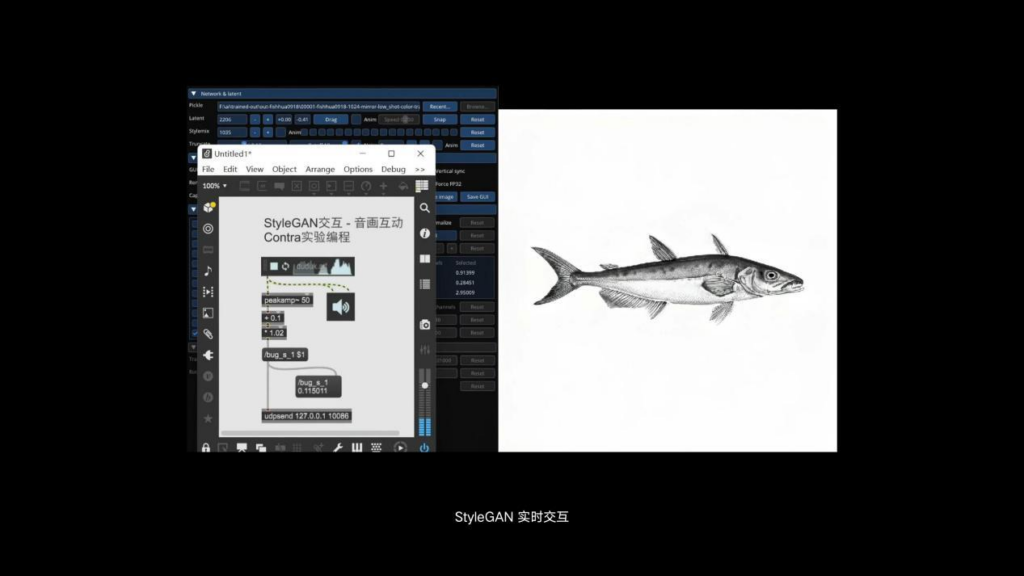
现在看到的是一个声音驱动的插值动画,StyleGAN的生成效率会比现在的AI高很多。这个动画的实现了画声实时互动的效果,音频在这里会作为另一种模态的数据来驱动这个画面,来改变当前这张图在潜空间里对应的数字。最终反映到人眼空间或者说像素空间里的画面就有了改变。也就是说你的数据来源不管是人机互动,还是传感器互动,或者来自于网络社会数据库里的一些文献的资料,总有一种数据可以和AI的生成关联起来。
刚才讨论的是StyleGAN,现在我们要说到目前大规模应用的扩散模型,比如Stable Diffusion和Midjounnry。什么叫扩散?因为它不像生成对抗网络,有一个生成器和一个判别器博弈对抗。如果在训练扩散模型时给它一张风景的图,然后一步一步给它叠加噪声,让它自己学着去反向操作这些过程。也就是把这些噪声一层层地去掉,之后就会得到新的一张图,尽量去接近那张原始的图,这就完成了一次学习。经过无数次这种学习后,你任意给它一张噪声图以及提示词,它就可以还原出你提示词的目标。这就是扩散模型。

这是我前两年用Stable Diffusion训练的一组作品叫《AI聊斋》,它用到的数据集是清代的一套绘本《聊斋全图》。我先去获得了古籍《聊斋全图》,它可以在“书阁”网站上公开下载。然后我就把它作为数据集训练之后去做了这样一个模型,有了这个模型就可以生成更多跟《聊斋全图》里的人物和画风相关的内容。现在图生视频非常方便,有了图顺便丢进去,几秒钟之后就可以拿到一个视频,这也就是模型训练的一个好处或者说意义。

上面三个是和《CyberFish》的联动。下面三个,中间的叫《陆判》,讲的是大家喝醉了吹牛逼,主人公去陆判的庙里面把陆判的塑像背回来了。后来真正的陆判在半夜就来找他,随之发生了一系列离奇的故事,比如给他的老婆换了一个头之类的。最右下角就是《画皮》和《聊斋全图》绘本里的角色一个样子。这段文案是聊斋志异书里的原文,我要训练这个模型,其实我要先教AI,告诉AI这张图代表的是什么内容,那么我就要去翻《聊斋志异》这本书。所以为了做这件事情,我其实被迫把《聊斋志异》又翻了一遍,这在无形中其实是很系统化的做数据收集和研究的过程。

有了模型在手,其实可以生成好多原来绘本里没有的关键帧或者分镜头。这集是《白莲教》,左边是原图,右边是《聊斋志异》原文,下边是我写的数据集标注。这个标注就是为了在训练过程中,告诉扩散模型这张图的用途,这张图里表有什么内容。经历这样一个过程的训练以后,就可以生成很多这一类的内容。这个故事其实很离奇,起因是主人公为了解救自己的妻儿,在被押送的过程中,突然出现了一个巨人把他们三个都吃掉了。但是巨人可能是到某一个地方会把他们三个再吐出来,也就是变相就把他们救走了。

这个是用“AI聊斋”这个模型做的一些新尝试。对于这种大画幅的作品,在前两年直接生成图还是有难度的,但现在可能有更多的办法。所以我也尝试创作了这种所谓极繁主义的作品,有非常多的细节,都是由AI生成,而不是单独创作后再把它们拼起来。

经过前面这些铺垫,大家可能已经简单了解了我是如何拿AI去创作,以及AI为什么可以被拿来做创作。那么接下来聊一下之前的算法生成艺术和AI之间的区别。这里可能有些关键词像“规则”、“流变”等等。所谓生成艺术其实是规则运行的痕迹。规则其实就是协议了,我们作为艺术家,尤其是跨媒体专业的艺术家,在创作算法生成艺术的时候,要先用代码来制定好一系列的规则。有了规则以后,通过一些实时的处理来最终形成自己的作品。艺术家不是为了直接绘制出最终的作品,而是在创作过程的起点,先制定一套规则。像维拉·莫尔纳(Vera Molnár)这套经典的作品《无序》,我们可以看到它背后有一种充满逻辑感和数学感的规则。
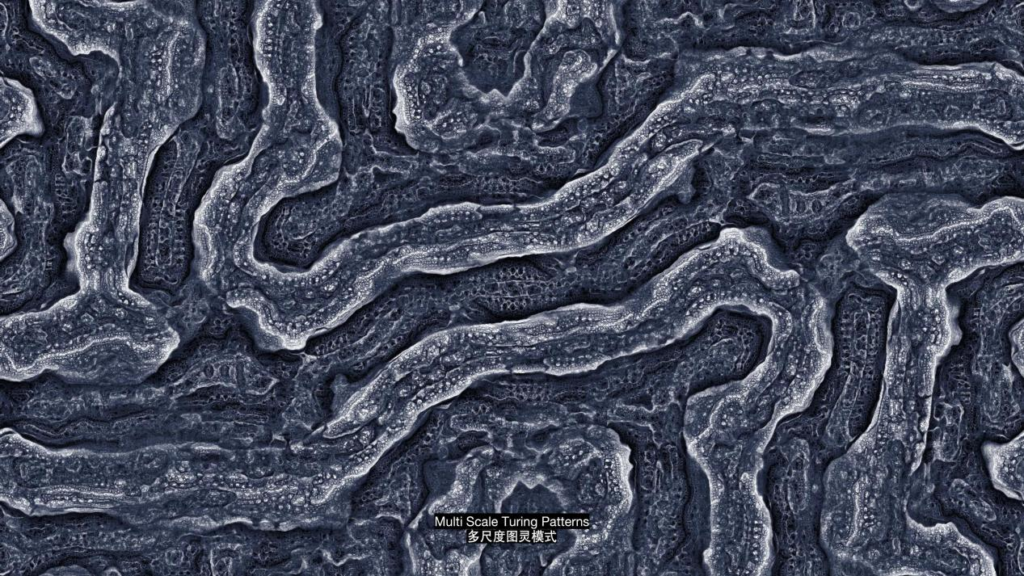
这个是三维的一种分形算法,制作这种作品的时候,只要通过算法和编程的方式把规则定好,通过艺术家给到的不同参数,计算机就会自动会帮我们生成这些作品。它跟直接拿笔画画还是不太一样的。拿笔画画你可能会从雕塑,或者其他的视角一步一步地去创造它。但是我们使用AI的时候,就需要先制定规则。像这种算法是多尺度图灵模式,它可能更多被用来生成模仿一些物体的形状,比如说地形的表面。像这个是跟电磁场有关的算法,这种数学算法本身很有一些美感,所以这些规则和算法通常被拿来做生成艺术。这是流体力学里的向量场算法,红线上的每一个点都有一个偏移量,把它连起来看就会形成一个向量场。基于这种算法,泰勒·霍鲍斯(Tyler Hobbs)创作了这件叫《Fidenza》的作品,在
NFT平台上卖的也非常好。

所以对于生成艺术的创作,艺术家其实是制定规则的人,然后由规则来产生最终的作品。这种规则通常是显性的规则,也就是说规则是可解释的。因为写代码的艺术家是规则的设计者,这种规则或者协议决定的是能发生什么,而不是决定最终的作品长什么样子,艺术家的关键是制定这个系统。作者性在这里其实也是很直观的。艺术家通过写代码得到一个program,这个程序包含了一套规则系统,当这个规则跑起来后就会得到最终的画面。
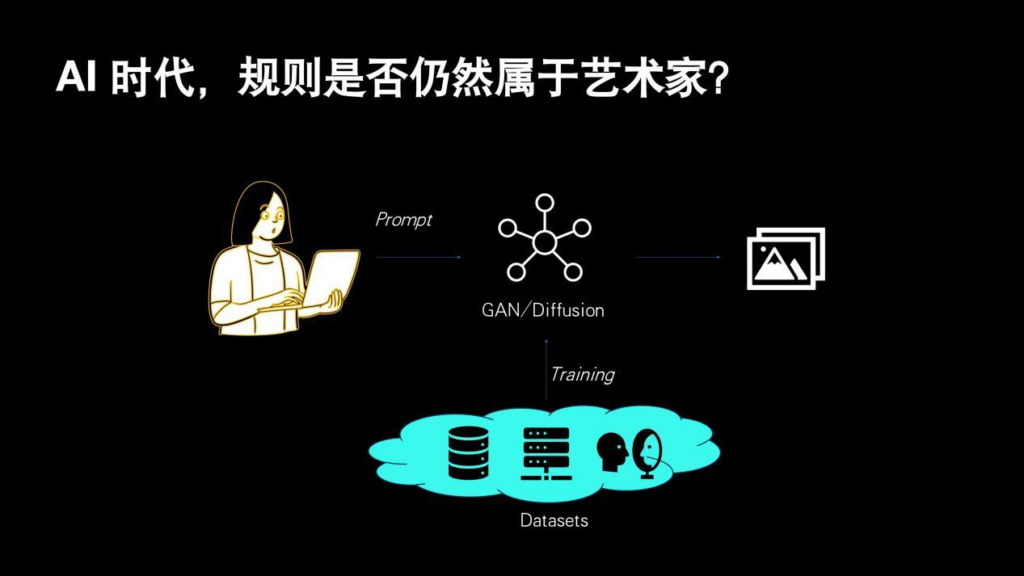
刚才我铺垫了那么多,但是到了AI时代,大家平时创作的方法变成了写提示词,然后由一个AI模型和这些提示词配合,最终生成内容。那么这时我们就有一个经常被讨论的话题:规则是否仍然属于艺术家?或者说所谓的AI艺术家是否存在?你拿AI去创作的时候,不管是写东西还是画东西,这个是你写的还是AI做的?但其实在AI里也是有规则的,但它的规则是潜在的。不像之前的算法生成艺术,我们直接在可读的代码里去写“if”等条件判断。对于AI,其实关键是机器自己学习规则,而不是艺术家去写这些显性的规则。AI从我们前面说的“a=2,b=3”这类数据集中,或者那些鱼的数据集,以及《聊斋全图》数据集里自己学习概率分布,在潜空间里面得到这种几何规律之后,进行推理约束和调度。但归根结底规则仍然存在。

那么我们作为艺术家如何去把控这种规则,或者说介入到这种规则里?可能我们刚开始用AI创作的时候会觉得比较无助,因为你能做的事情好像只是写提示词,剩下的那些AI都帮你完成了。但实际上这里边有很多意思不明确的词,会提示你它的作用。比如最左边的是生成式AI,它是有一个潜空间和插值动画,中间是扩散模型,它是从一个噪声值开始一点点扩散,最右边的是现在比较新的自回归模型。自回归模型它更像是以时间的维度去关联前一帧和后一帧,所以在模型内部就具备了因果的理解力。之前的模型生成一次就是一张图,哪怕生成视频得到的也是多张图的序列帧,它的前后内容在逻辑上其实是没关系的。但是到了现在,它能根据之前的内容来推测后面要发生的事情,其实就有了因果。这个时候的作品就是一个完整的轨迹与序列。那么在潜空间里通过这种插值,你其实就可以做一些创作而不只是写提示词。在自回归模型甚至是在扩散模型里,随着生成过程的展开,其实每一步我们都可以修改很多参数。尤其当我们作为一个算法工程师或者算法艺术家时,即使给到AI同一个提示词,也就是说给它同样世界观的时候,我们还是能做出很多内容,这其实就是一个人机交互的动态过程。在我们反复尝试使用模型后会得到一个谱系,在这个谱系里通过不断地反馈,通过这些反馈去调整输入的关键词,就会最终生成闭环的作品。
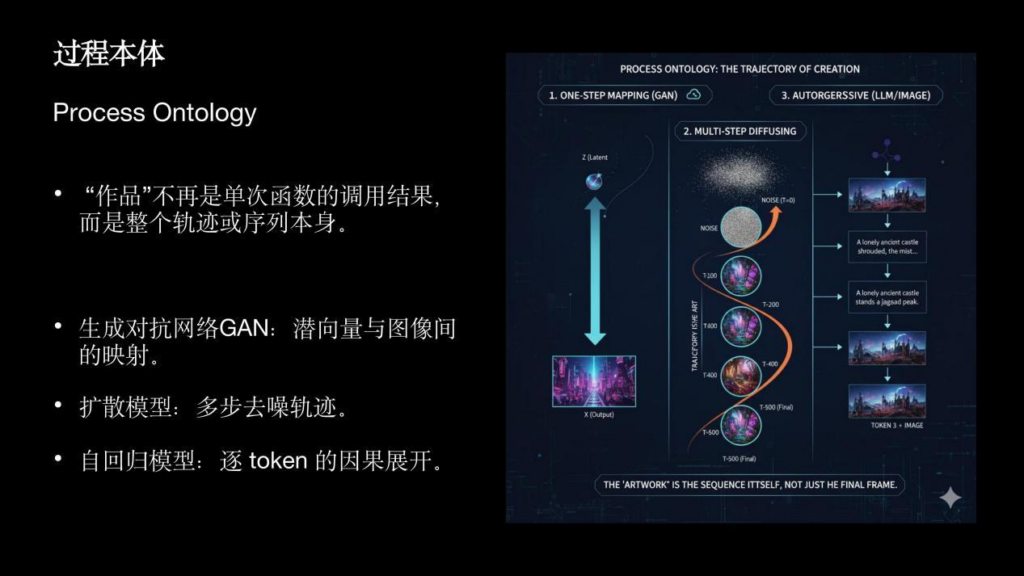
可适应的权重,涉及到“遗忘”。比如说我训练我的鱼的时候,我让AI遗忘了本来模型里的老虎,通过鱼的数据集把它训练成了一个生成鱼的模型。让它忘掉自己的东西,但是记住我想让它记住的东西。作为创作者,总是可以跟AI发生相对深度和细节的对话,而不只是有一些提示词。所以创作过程不是在一个固定的世界观里展开的,我们其实可以主动去重塑这个世界。所以,从传统的算法生成艺术,到现在的AI生成,我们要再做一次对齐。我们有时候会把传统的算法生成艺术,叫做旋钮艺术或者调参艺术,好像改几个参数画面就变了,但实际上不是这样的。艺术家是在创作规则,打造系统。在AI时代,这个问题被抛回来了:创作的主体性是否仍然属于艺术家?我觉得没有那么的悲观。我们能做的事情其实非常多,不只是提示词,我们甚至可以把一个模型带偏,这已经是人类主动性很大的体现。

这是关于网络社会以及新媒体艺术的一些“老黄历”,我的社群“实验编程”是一个创作者社群以及知识输出平台。可能从08、09年开始,有一个比较活跃的交互媒体论坛“who do it”,这是它的前身。其实最早的群体活跃在豆瓣小组,后来做了论坛,然后就一直发展到现在。大概是这样一个过程。这个也是蓬岸一直在跟我交流的一些东西:这群人的过去和现在,以及他们所代表的一种创作生态和技术,在AI前和AI后产生了哪些创作感受。谢谢大家!
——————————————————
提问环节
Q1:谢谢罗老师演讲,我问一个细节问题,就是关于你那个鱼在潜空间里面不同的层次。你表述的就有点像是我们画画的过程:先打个大形,然后再搞细节。我不知道这种算法是被设计成先把握大形再细节,还是说这种秩序本身也是机器自己摸索出来的,又或者反过来问:是否它可能把握起来不是那么直观,有没有其他不同层次的秩序?
A1:这个问题挺专业的,如果我们从一个整体的层面来讲,AI对于人可能是一个黑盒子。比如说Open AI的人训练好ChatGPT以后,算法工程师并不知道GPT里边如何实现那些步骤。但是他知道AI如何去训练,这是一个特点。所以在鱼那里边,首先我选的是生成对抗网络。网络会分几个大的层,基本它的一个结构就是AI的结构。它是会先抓主体,然后再去完善细节。但是主体究竟是怎么抓取的,或者说细节究竟是怎么完善的,这些是AI通过自己的学习和归纳找到了那些数据的分布规律。我不知道它怎么画出来的,但是它能画出来。但是当你给它的设计结构就是大的训练结构的时候,它确实是有可能在前面的层偏向于大体的特征,后边是一些细微的东西。包括后来的扩散模型,也是会优先去会画大的结构,但是每一步细节都是黑盒。
Q2:非常感谢罗老师,在我们跨媒体艺术学院当中,有一些部分学生是懂一点点编程的,特别是开放媒体系,像武子扬他们。但不管展研还是我们网研,基本上都离程序比较远。所以同学们的担心有时候会压过他们实际尝试的勇气,就觉得好像那个东西离他们越远越好。我只是好奇,对这些应该感到兴趣以及抱有实验精神的学生们,我们怎么鼓励他们去尝试这种新的创作?
A2:您是说我是否要给一些建议是吗?因为现在AI,尤其商业模型的成熟度,它的门槛是非常低的。以前做这种尝试,要搭建的前期基础工作有很多。相比起来,现在借助AI做任何尝试其实都非常简单。我觉得这个问题的答案没有no,敞开去使用就好了。当然可能你们这个专业有很多值得思辨的地方,我觉得是非常好的。包括我现在最近在创作的一些内容,我用AI去直接帮我生成代码,然后再去跑一些东西,你会发现AI对自己生成的内容有非常自洽的逻辑。但抛开它写的那些代码仔细去看的话,其实还是有一定的问题。但是如何去发现AI的这些问题,可能需要大家平时更多地实践。
Q3:罗老师,我其实对您的职业历程比较感兴趣,您是怎么从游戏行业进入到新媒体艺术行业?比如说05年、20年这种关键的节点是什么?是线上还是线下去开启了职业路程?
A3:你这问题太好了,我特别爱聊。首先开发游戏和新媒体艺术,在技术层面是一致的。所以我在做游戏主业的同时,我还能用副业做一些创作类的事情,或者说做一些相应的项目,这是顺理成章的事情。契机是我05年上研究生的时候,我在北航,离清华不远。当时清华美院也刚开张几年,那时候大学都很开放。他们有一次请了比利时的一个新媒体艺术团队来进行三天的工作坊。可能就五六个人,我无意中遛弯的时候发现了他们,然后就进去听了三天的课,跟着他们做工作坊,也没有人管我是不是清华的人。我当时觉得还很有意思,而且其实跟我做的事情在逻辑上是一致的,只是可能从思路以及世界观方面是有不同,所以我大概从那这样一个契机开始了一个旅程,谢谢你。
——————————————————
讲者介绍
创意演讲嘉宾 罗霄

罗霄,算法工程师,数字艺术家。实验编程创始人,从事交互媒体、人工智能、生成艺术的创作与教学。同济大学建筑城规学院AI与艺术创研中心实践导师,AI艺术创新联盟AIAIA常务理事。毕业于北京航空航天大学,电子信息工程与软件工程专业背景。曾就职于腾讯ISUX和网易游戏。2005年起从事游戏开发与新媒体艺术类项目,2020年引入AI技术重构创作范式。个人作品于中国、英国、日本、南非、意大利等地展出。